Barnes-Hut N-Body Simulation in CUDA
15-418/618 Spring 2026 — Midterm Report
Andrew Koulogeorge
Proposal | Midterm | Final Report | GitHub
Project Schedule
✓ Completed
○ Planned
Week 1 (Mar 30 – Apr 3) — Literature & Sequential Baseline
- Read Barnes-Hut algorithm literature and GPU implementation papers
- Implemented single-threaded C++ version of Barnes-Hut
- Verified correctness against brute-force O(N²) reference
- Measured sequential baseline performance across several N values
Week 2 (Apr 6 – Apr 10) — Initial CUDA Version & Profiling
- Implemented initial Barnes Hut CUDA V1 with optimized tree representation (still naive tree traversal, poor localtiy)
- Implemented brute force CUDA version and implement test case suit to ensure correctness of array based OctTree representation and Barnes Hut CUDA V1
- Benchmark Barnes Hut CUDA version V1 against brute force CUDA, Barnes Hut CPU
Week 3 (Apr 13 – Apr 17) — Optimization Iterations
- Implement remaining paper optimizations: improve locality of tree traversal, add node sorting kernel
- Benchmark final implementation speedup and identify bottlenecks via Nsite profiler for further optimizations
- Begin drafting final report and poster outline
Week 4 (Apr 20 – Apr 24) — Finalization & Presentation
- Finalize written report
- Prepare and present poster (Apr 24)
Poster Session Plan
What I Plan to Show
- Problem Background: N-body visualization, OctTree
- Overview of GPU implementation (what each kernel does for v1, sequential OctTree representation)
- Key Ideas of each implemented kernel and how the implementation of some kernels evolved (ex: how synchronization is implemented in a lock-free way)
- Side-by-side speedup comparison: sequential C++ → CUDA V1 → CUDA V2 → (V3 if time allows)
- Scaling curves across number of bodies N and approximation threshold theta
- Identify remaining bottlenecks: what is preventing the solution from getting even faster?
- Table showing connections with course content (there is so many; SIMD, memory consistency, lock free programming, sequential graph representation, ect)
Results So Far
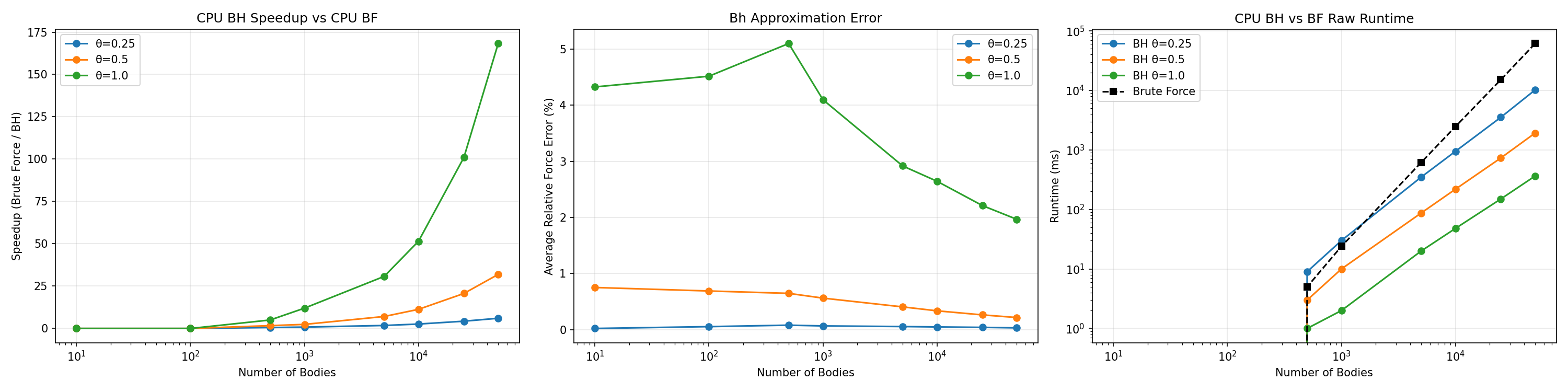
CPU Benchmark
CUDA V1 Benchmark

Profiling — V1 Kernel Analysis
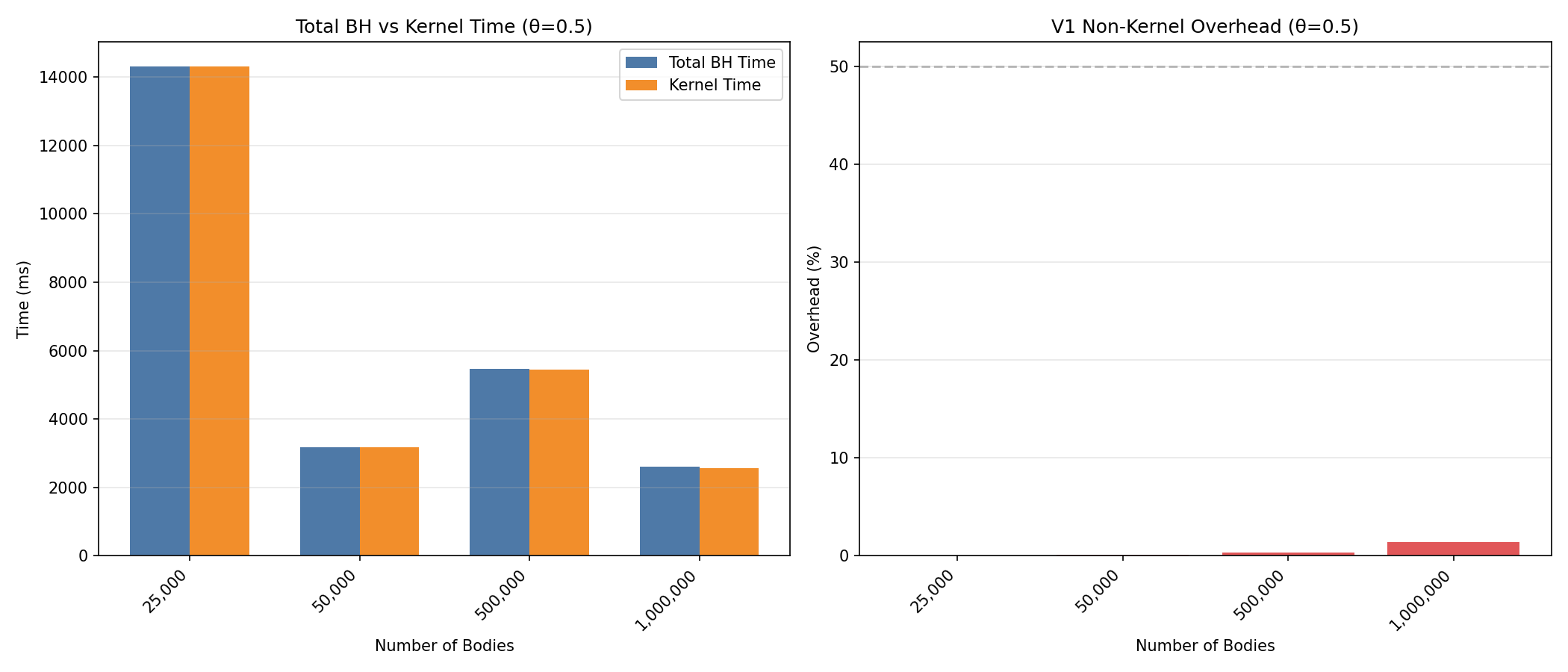
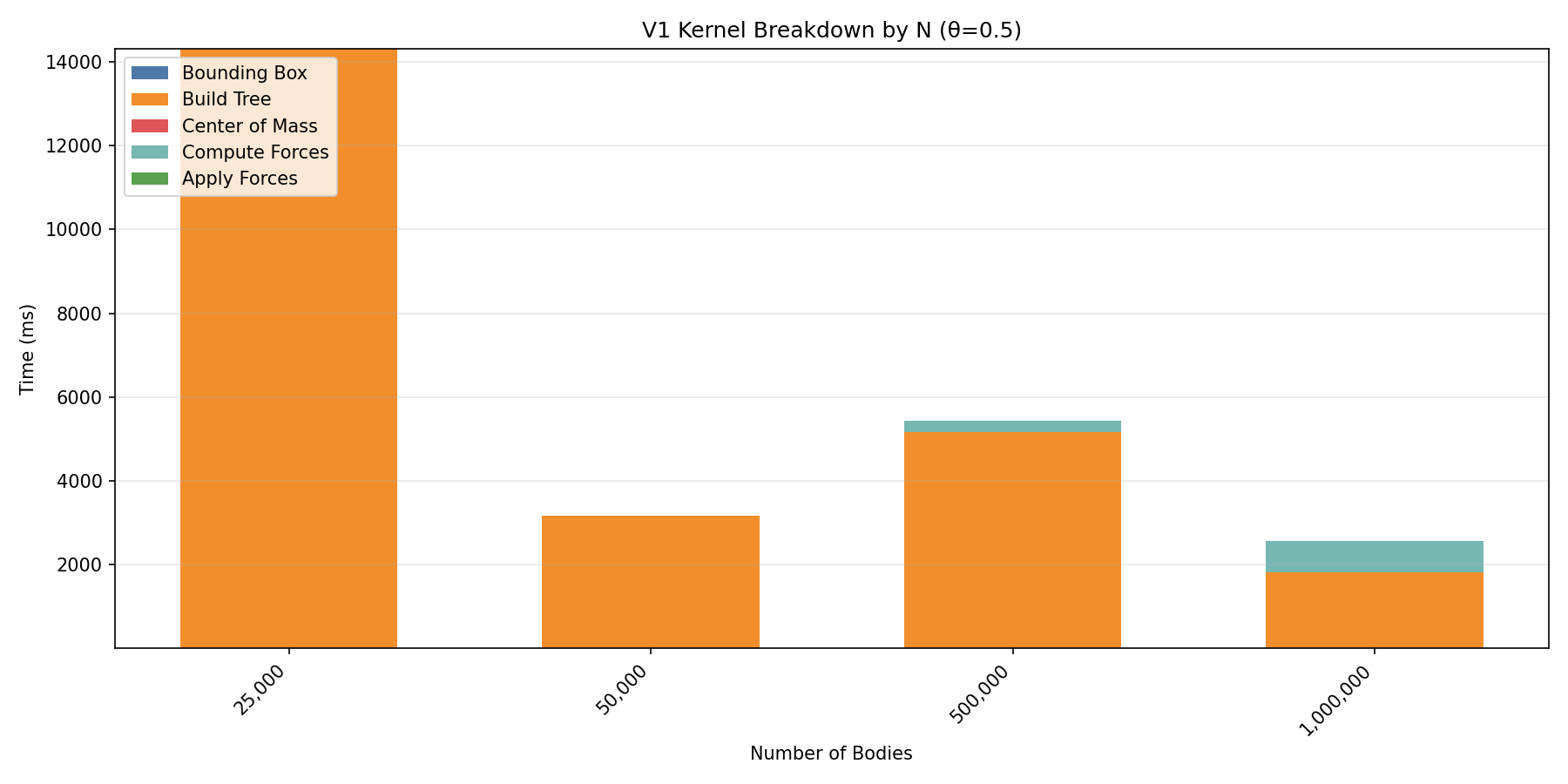
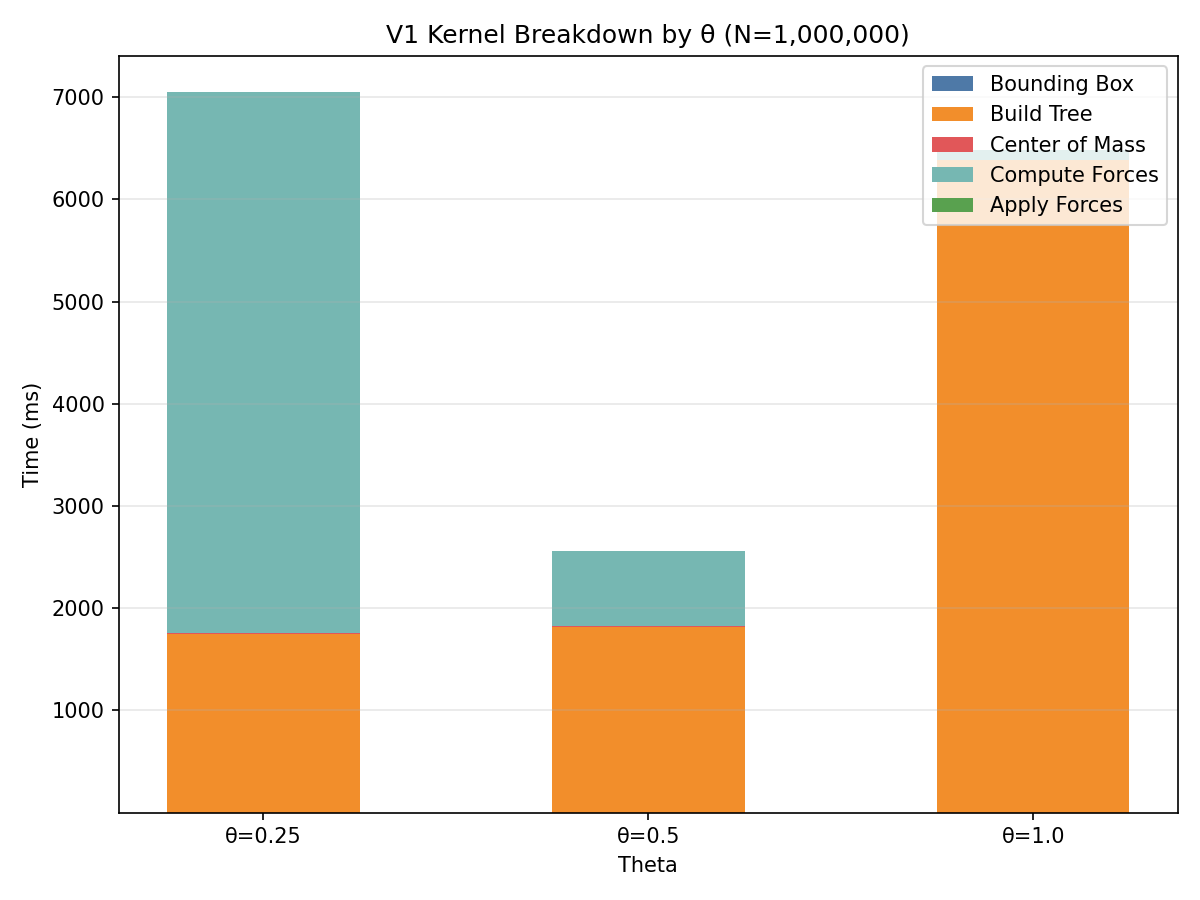
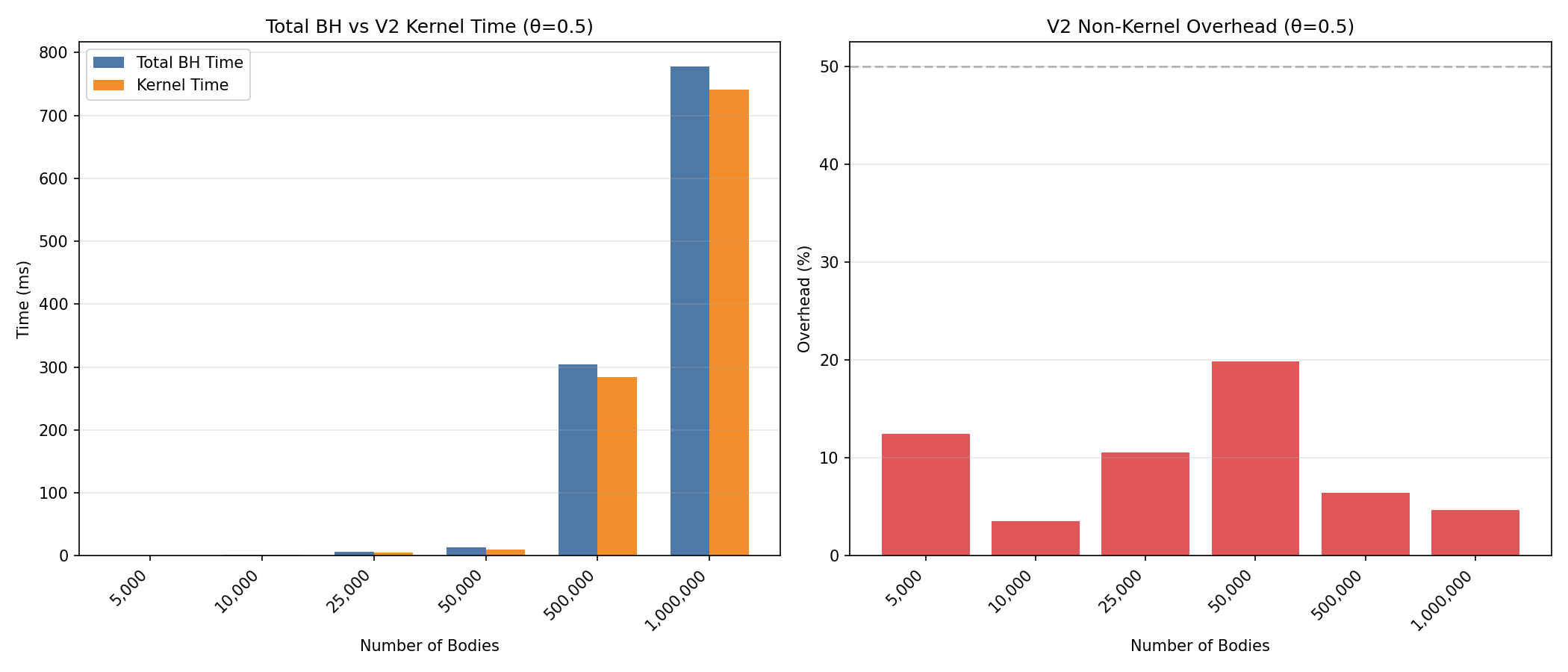
CUDA V2 Benchmark

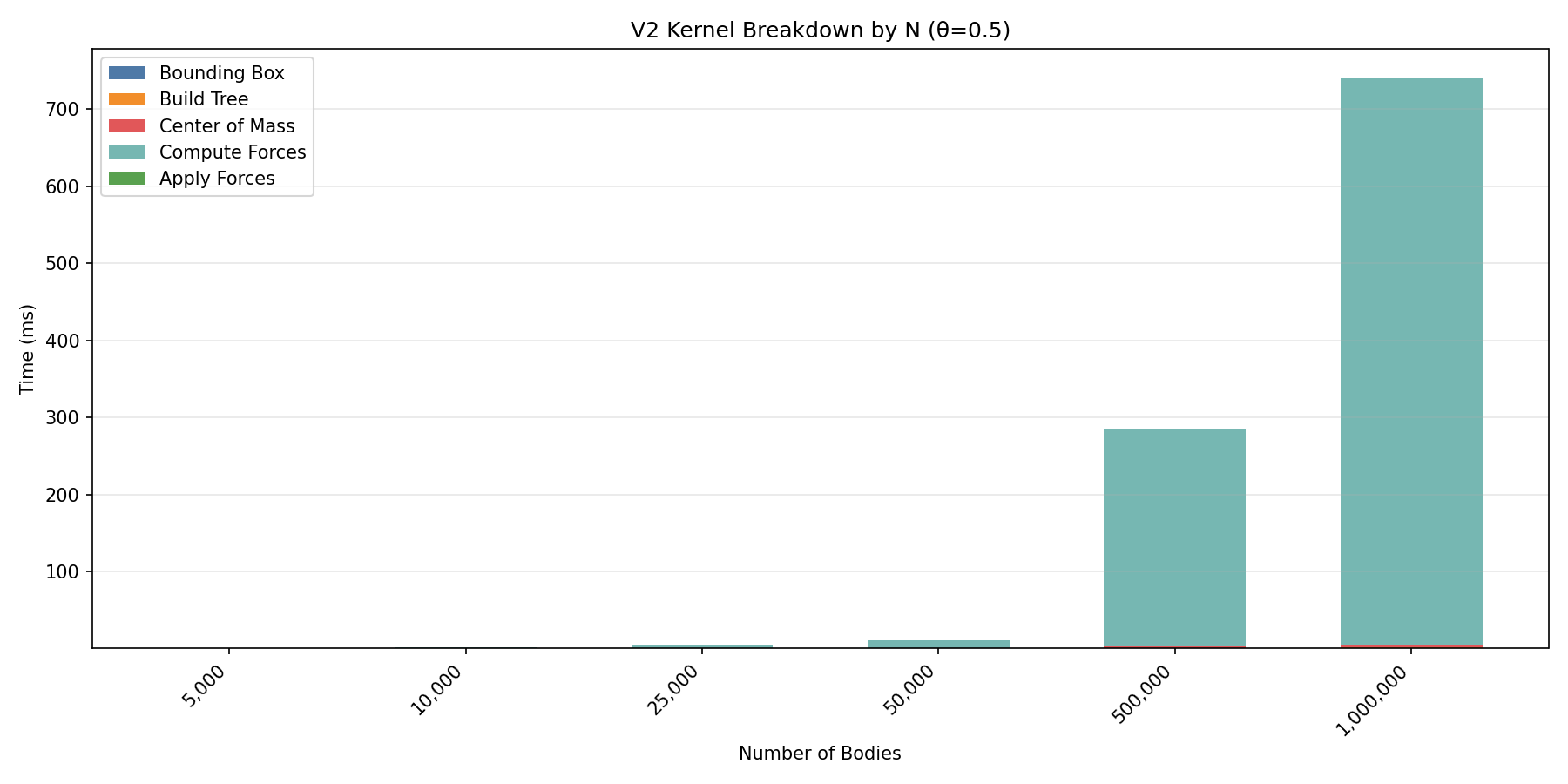
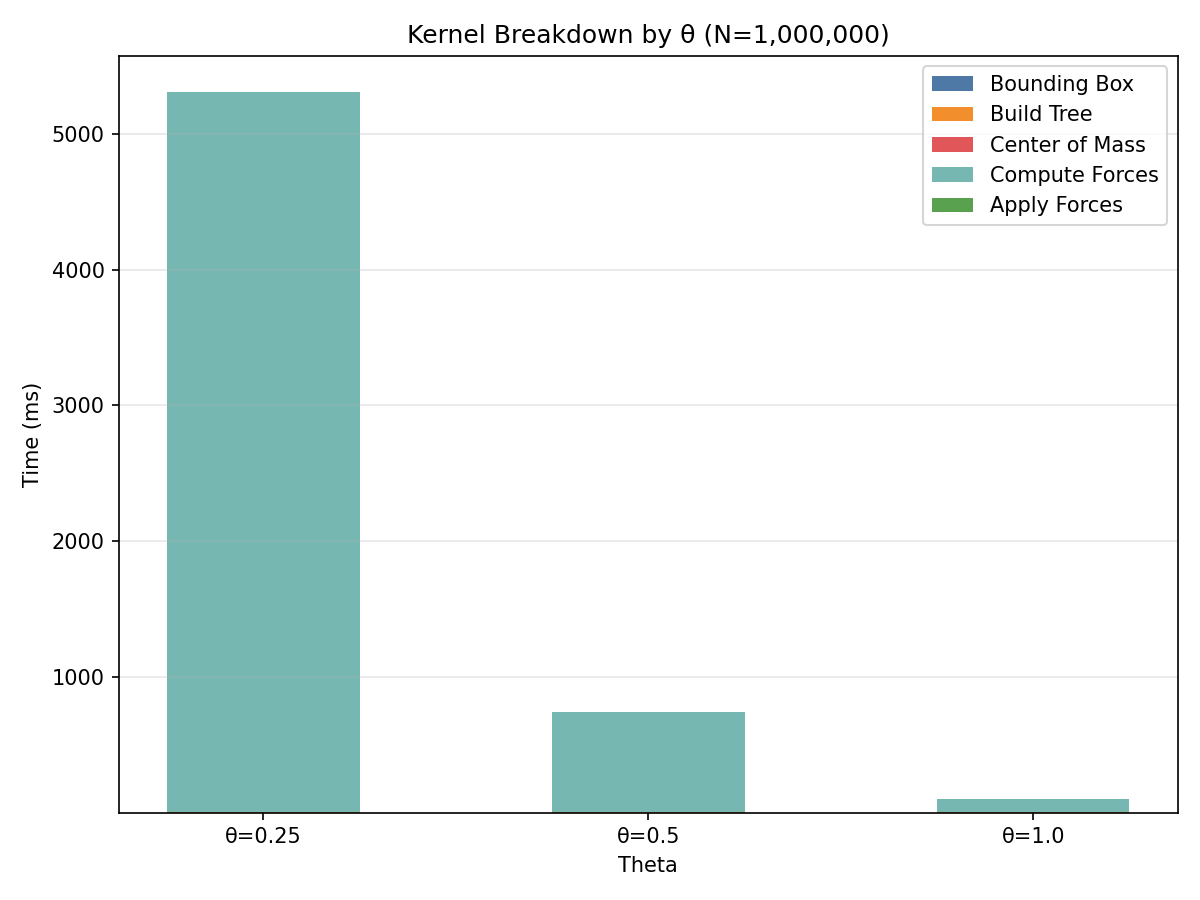
Profiling — V2 Kernel Analysis