Summary
I am going to implement the Barnes-Hut N-body simulation algorithm from scratch in CUDA and do detailed profiling and analysis to understand its behavior and optimize its performance through several iterative implementations. I will evaluate performance across different problem sizes, initial body configurations, and approximation thresholds.
Background
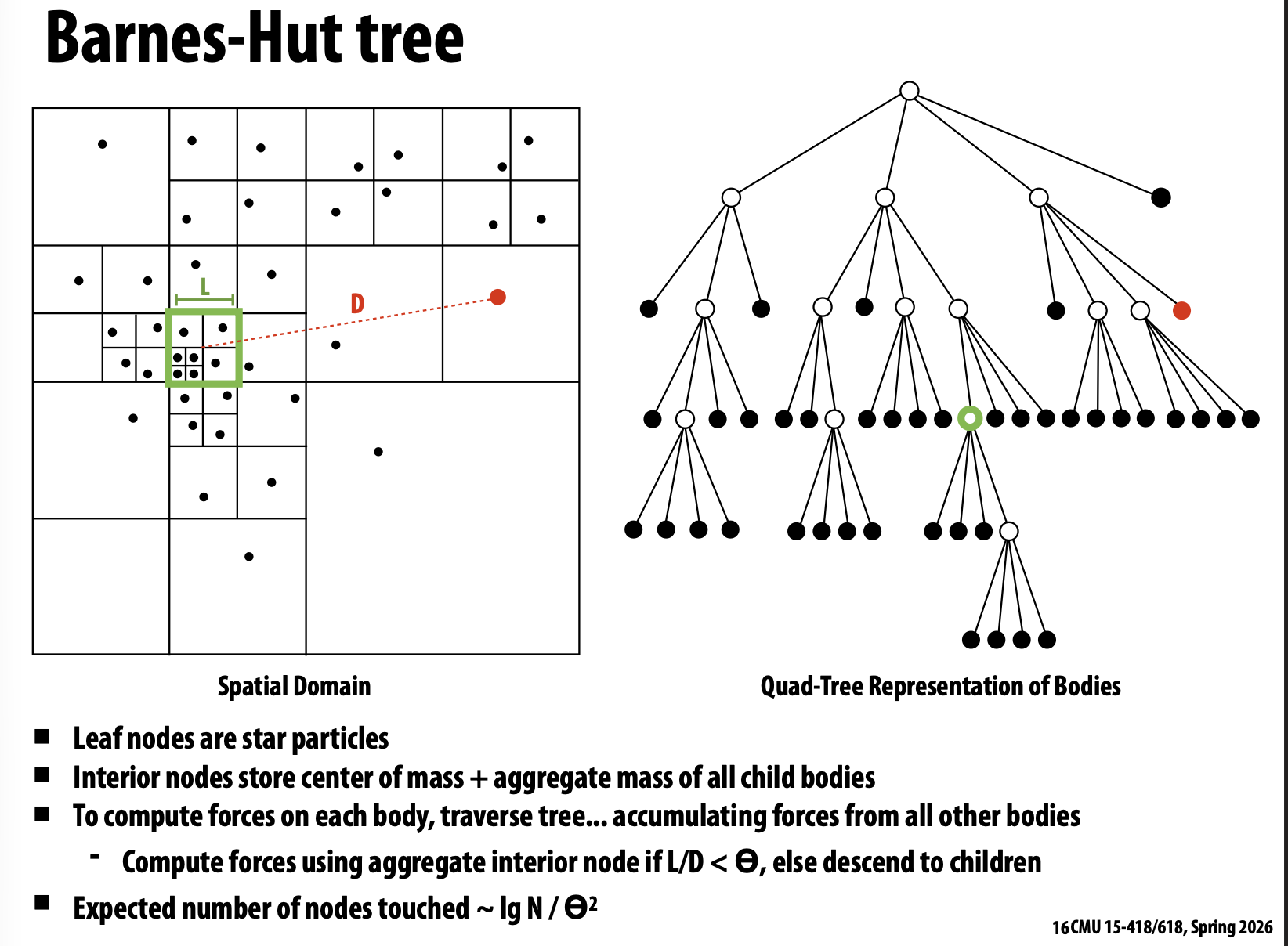
The Barnes-Hut algorithm estimates pairwise gravitational forces between a collection of N bodies by approximating groups of bodies sufficiently far away as a single body with a corresponding center of mass. This reduces the complexity of the algorithm from O(N²) to O(N log N).
The input data to the algorithm is a collection of points in 3D space. The main computational
loop includes: (1) constructing an octree where each node represents a region of space,
(2) computing the center of mass for each node in the tree, and (3) traversing the tree to
compute the gravitational force on each particle.
Learning Goal
Gain experience in performance engineering and analysis in a setting outside a problem set with standard performance benchmarks. This project is very similar in flavor to one of the 3 programming labs during the semester. With a longer timeline and less pressure to hit a fixed performance threshold, I am excited to gain experience with profiling tools and obtain deep insight into various aspects of this parallel program.
The Challenge
The structure of the tree is data-dependent and changes across time steps, creating several parallelism challenges (non exhaustive list):
- Computational Dependency: The tree must be fully constructed before gravitational forces can be estimated, creating a sequential bottleneck between phases.
- Memory Access Patterns: The tree data structure may not be laid out contiguously in memory, harming cache performance during traversal and resulting in lots of pointer chasing.
- Load Imbalance: Densely packed clusters of bodies require deeper tree traversals and more computation than isolated bodies, leading to uneven work distribution across threads.
- Divergent Execution: The depth of tree traversal varies per body, causing warp divergence on the GPU where threads in the same warp take different control-flow paths.
- Spatial Locality: Bodies nearby in space touch similar portions of the tree.
Resources
I will use the NVIDIA GPUs available on the GHC cluster machines. I am starting the implementation from scratch. I plan to reference various online resources and papers related to Barnes-Hut implementations in CUDA, but not simply reimplement them. I want to explore my own ideas for optimization based on my own measurments. Barnes-Hut on Wikipedia Barnes-Hut on GPU
Goals and Deliverables
Plan to Achieve: Implement a sequential Barnes-Hut algorithm in C++. Implement a naive CUDA version and at least two optimized CUDA version driven by profiling data. Evaluate how each implementation scales across: number of bodies, initial spatial configuration, and the theta threshold for force approximation. Compare my best implementation against published state-of-the-art GPU Barnes-Hut implementations.
Hope to Achieve: Analyze performance of CUDA code on a different GPU generations hypothesize about causes of performance differences based on architectural details.
Poster Deliverable: Present a comparison of my implementations against a sequential baseline with analysis of the measurements and profiling data that motivated each optimization. Included detailed analysis of my best implementation. Include comparison against existing state-of-the-art implementations.
Schedule
- Week 1 (Mar 30 – Apr 3): Read literature on Barnes-Hut and GPU implementations. Implement and test single-threaded C++ version. Measure baseline performance.
- Week 2 (Apr 6 – Apr 10): Implement initial CUDA version (V1). Profile with Nsight. Identify bottlenecks and implement optimized V2 based on measurements. Milestone Report due Apr 14.
- Week 3 (Apr 13 – Apr 17): Continue optimization iterations based on profiling. Begin drafting final report and poster outline.
- Week 4 (Apr 20 – Apr 24): Finalize implementation and run scaling experiments. Polish report and prepare poster materials. I will be giving my final presentation on April 24